Java is Very Fast, If You Don’t Create Many Objects
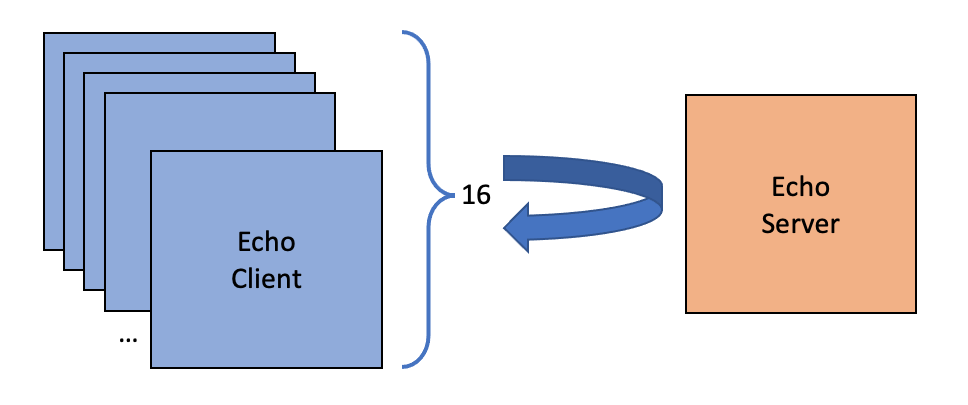
You still have to watch how many objects you create. This article looks at a benchmark passing events over TCP/IP at 4 billion events per minute using the net.openhft.chronicle.wire.channel package in Chronicle Wire and why we still avoid object allocations.. One of the key optimisations is creating almost no garbage. Allocation is a very cheap operation and collection of very short-lived objects is also very cheap. Does this really make a difference? What difference does one small object per event (44 bytes) make to the performance in a throughput test where GC pauses are amortised? While allocation is as efficient as possible, it doesn’t avoid the memory pressure on the L1/L2 caches of your CPUs and when many cores are busy, they are contending for memory in the shared L3 cache. Results Benchmark on a Ryzen 5950X with Ubuntu 22.10. JVM Vendor, Version No objects Throughput, Average Latency* One object per event Throughput, Average Latency* Azul Zulu 1.8.0_322 60.6 M event/s, 528

